One thing to keep in mind here which is different from setting up traditional vPC is that, in a VXLAN EVPN fabric with vPC Fabric Peering, you must allocate TCAM resources to the ing-flow-redirect region with a minimum value of 512 so the switch can handle traffic redirection between vPC peers. This enables hardware-based flow processing required for functions like virtual peer-linking, Anycast Gateway support, and VXLAN encapsulated traffic forwarding between vPC members.
Without TCAM allocation, features like peer-gateway, ARP/GARP replication, and ingress redirection will not function, leading to blackholing or asymmetric traffic behavior.
Now let me give a low level explanation of TCAM and why we need it in this context:
Imagine two best friends (switches) working together to serve you candy (data). They promise to always share, but they need a special notebook to remember who took what and when. If they don’t have that notebook, they can forget your order, or worse, both try to deliver it and cause chaos.
In your switches, that “notebook” is TCAM (Ternary Content-Addressable Memory). A super-fast memory used to match complex rules like:
“If this VXLAN packet comes in and it’s for this MAC, then forward it through that peer.”
Now, when you use vPC Fabric Peering, you’re saying:
“Dear switch, instead of a physical link, please remember how to forward traffic to your peer using VXLAN tunnels.”
To do this, the switch needs pre-allocated memory space (TCAM region) to install and match redirection rules.
Now let’s talk about why we really need TCAM at a more advanced level:
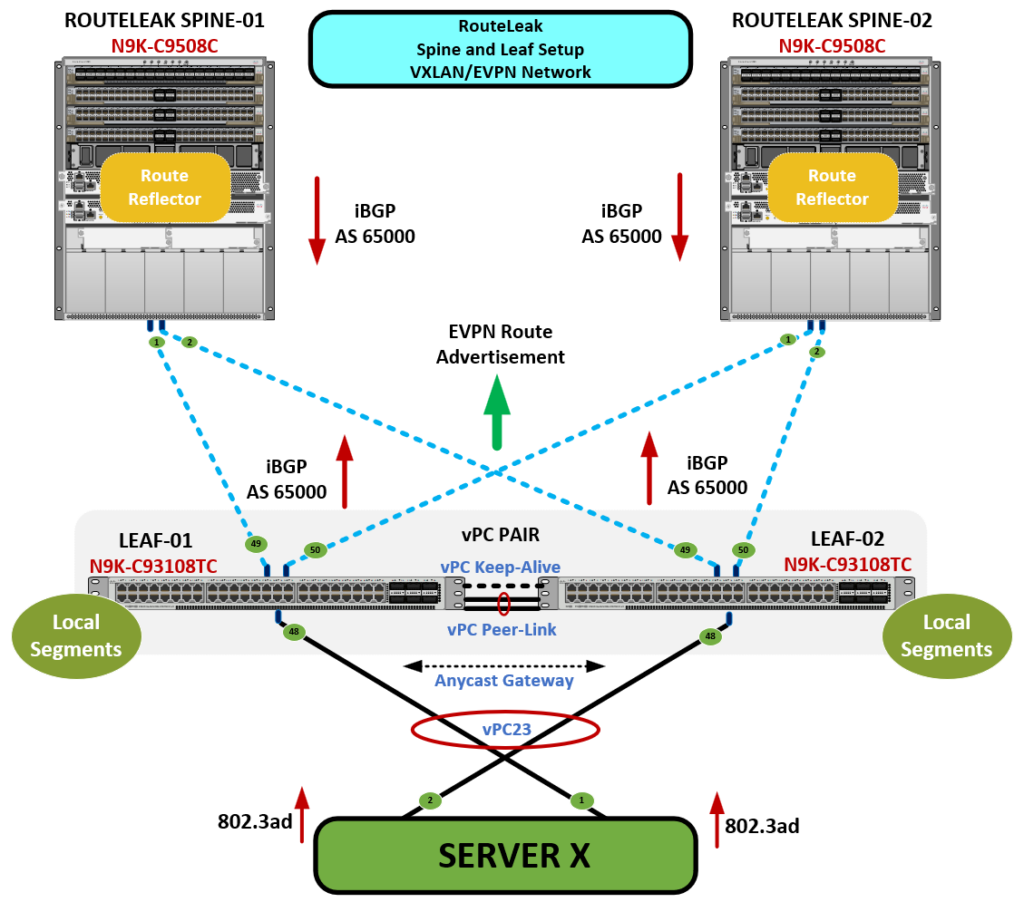
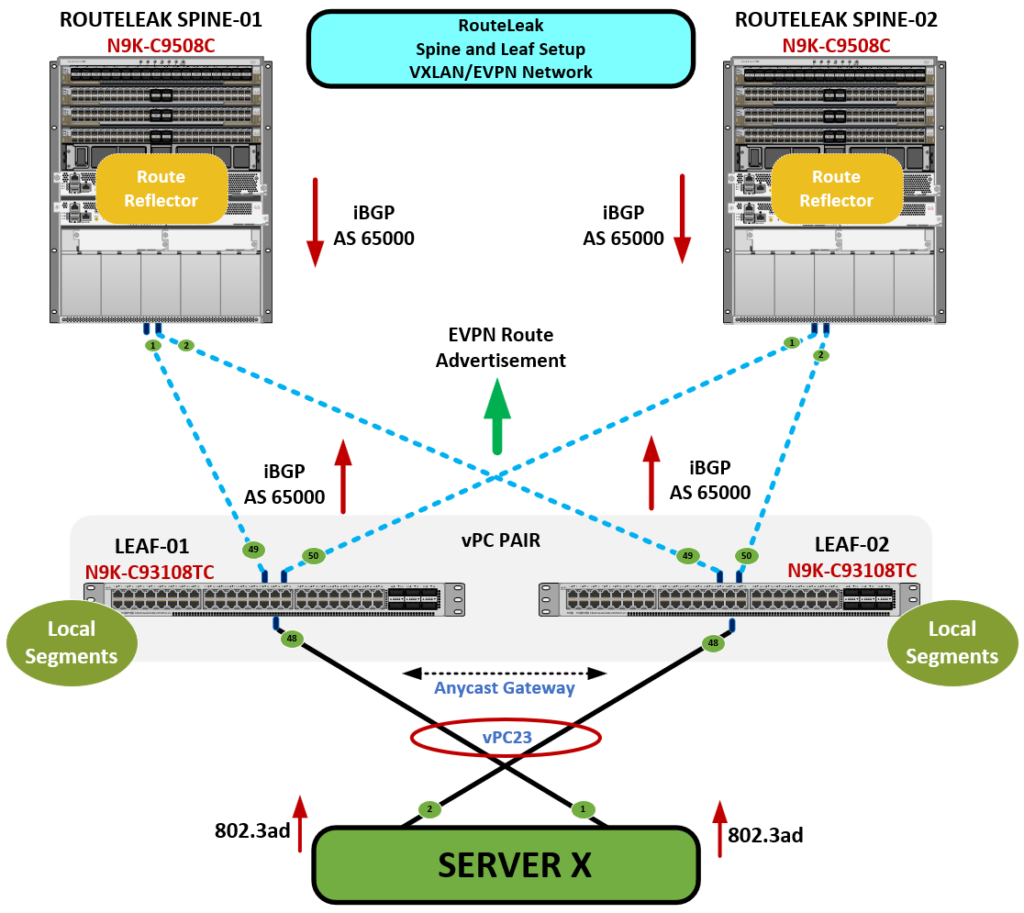
✅ 1. vPC Virtual Peer-Link over VXLAN Needs Redirection
- In traditional vPC, the peer-link is a Layer 2 trunk and traffic redirection is implicit via bridging.
- In vPC Fabric Peering, the “peer-link” is virtualized over VXLAN tunnels using NVE interfaces.
- This redirection is done via Ingress Flow Redirection, which needs hardware TCAM entries to match VXLAN traffic that must be sent to the vPC peer.
✅ 2. ARP/GARP/DHCP Flood Handling
- ARP and DHCP requests from a dual-homed host must be replicated and delivered consistently to both leafs.
- If a vPC peer receives an ARP request but doesn’t have the MAC/IP mapping, it must redirect it to its peer.
- That redirection behavior is handled via flow redirection entries in the TCAM.
✅ 3. Anycast Gateway Peer-Gateway Function
- The Anycast SVI IP/MAC is shared between the vPC peers.
- When Host-A sends a packet to the gateway MAC, the switch might not own the original entry but must process or forward it on behalf of its peer.
- That operation again uses redirect entries to the remote peer VTEP, requiring TCAM usage.
✅ 4. EVPN MAC/IP Learning Optimization
- In a VXLAN EVPN setup, each switch learns local MACs and advertises them over BGP EVPN.
- To ensure deterministic and symmetric traffic flows—especially in asymmetric IR models—the hardware needs to process the MAC/IP bindings against encapsulated VXLAN headers.
These complex match-actions are stored in TCAM.
Let me show you how to get it configured. First we need to check the TCAM resource allocation on the switch to verify whether ing-flow-redirect has been carved and how much space is allocated by running the below command.

 Hi, I'm Pape ! Folks call me Pop. I'm CCIE #48357. I love what I do and enjoy making tech easier to understand. I also love writing, so I’m sharing my blog with you
Hi, I'm Pape ! Folks call me Pop. I'm CCIE #48357. I love what I do and enjoy making tech easier to understand. I also love writing, so I’m sharing my blog with you