
Welcome to the Network Engineering Domain
Pape O. Fall's Blog
Have you heard of something called “The Internet” ? Well, BGP is actually the routing protocol that makes it all happen ! I would like to start off by saying BGP is by far my FAVORITE routing protocol ! By Far !!! Did I say by far ?! Not even close to the other ones !
Okay, BGP stands for Border Gateway Protocol and it is primarily designed to support the magnitude and complexity of the Internet. That’s basically the protocol that connects the different ISPs. However, it is also used in certain circumstances by large enterprises to connect to their respective ISPs. For this section, we will use the following topology and our goal here is to successfully advertise the loopback address from R1 perspective and receive it on R6…

BGP is different from IGPs such as OSPF, RIP or EIGRP in a sense where it is considered as an EGP (Exterior Gateway Protocol). It is to this day, the only EGP used in large scale network. There used to be another protocol called EGP which is now replaced by BGP. At this point, it’s important to know that IGP is not equal to EGP. So, IGP refers to the process running on L3 devices inside a network (Within an Autonomous System) while EGP refers to the process running between L3 devices bordering directly connected Service Provider’s network (Between Autonomous Systems).
Also it is important to remember that BGP runs over TCP – Port 179. So if you have a firewall in front of your internet router, make sure you allow port 179 (TCP).
In order to really understand BGP, understanding how it differs from other routing protocol (IGPs) is imperative. Let me explain…
If you look at the diagram above… For AS200 to send traffic to AS100 (Let’s say the loopback address), here is what needs to happen:
*AS100 must originate and announce the loopback prefix
*R2 in AS65123 will need to accept the loopback prefix from AS100
*R2 must then announce the prefix to R3, R4 and R5
*R3, R4 and R5 must accept it
*R5 must accept it and must announce it to R6
*R6 then must accept the prefix
Did you see how we went backwards to fulfill the connection requirements (From AS200 to AS100) ? If 2 way packet flow is required, then the same analogy needs to happen from the opposite direction.
BGP typically learns multiple paths to a destination via both internal and external speakers. It picks the best path by going through a best path selection process and install it in its forwarding table. The best path is sent to external BGP neighbors and you could also apply policies to influence the best selection.
Let’s talk about BGP best path selection algorithm before we hop onto the consoles…
1) Prefer the path with the highest “weight” (Weight is a Cisco proprietary attribute and it is locally significant to the router. It is set to 0 by default)
2) Prefer the route with the highest Local Preference (By default the LP is set to 100 and it is propagated within the AS)
3) Prefer locally originated route via a network or aggregate command or via redistribution from an IGP
4) Prefer the route with the shortest AS path
Most of the time, by this point BGP would complete a path selection based on the above sequential preference rules. If not, then it would keep going as such…
5) Prefer the lowest “origin code” (IGP is lower than EGP. EGP is lower than INCOMPLETE)
6) Prefer the path with the lowest Multi-Exit Discriminator or MED (MEDs are compared only if the first AS in the AS_SEQUENCE is the same for multiple paths. Any preceding AS_CONFED_SEQUENCE is ignored)
7) Prefer eBGP over iBGP paths
8) Prefer the best IGP path to the BGP next hop
9) Determine if multiple paths require installation in the routing table for BGP Multipath, if not go to 10
10) When both paths are external, prefer the path that was received first (the oldest one)
11) Prefer the route coming from a BGP router with the lowest router ID
12) If the originator or router ID is the same for multiple paths, prefer the path with the minimum cluster list length (Only in BGP RR environment)
13) Prefer the path that comes from the lowest neighbor address
At this point, BGP should already made up its mind right ? Let’s hop onto the consoles now…
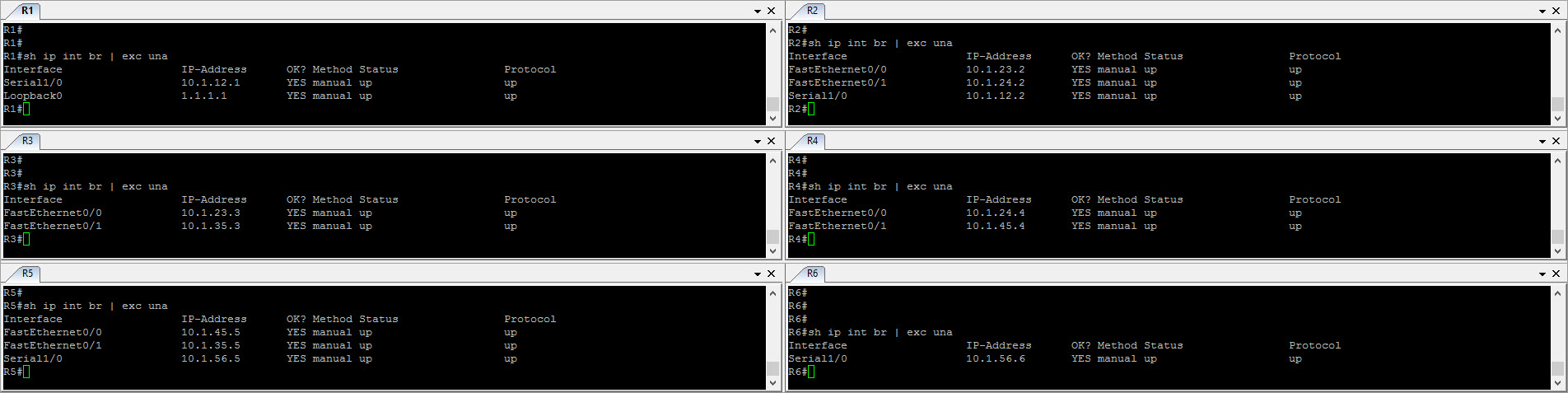
As you can see here, all IP addresses have been pre-configured. Let’s start by configuring OSPF as our IGP in AS 65123.
Note that the reason why we need OSPF in AS65123 is typically we’d want the iBGP speakers to be fully meshed for many reasons such as scalibility, ease of management and deployment, preventive measures in terms of downtime. We’d also want to peer with iBGP neighbors sourcing from loopback interfaces which never goes down. Hence, providing a great deal of redundancy. Most of the time, ISPs uses Link-State protocol such as OSPF which from a router perspective, knows the entire routing information of the network which then provides a great deal of flexibility when it comes to traffic engineering. Let’s start by configuring OSPF in AS 65123. At this point, if you are unfamiliar with OSPF, I’d suggest to read about this post here first…
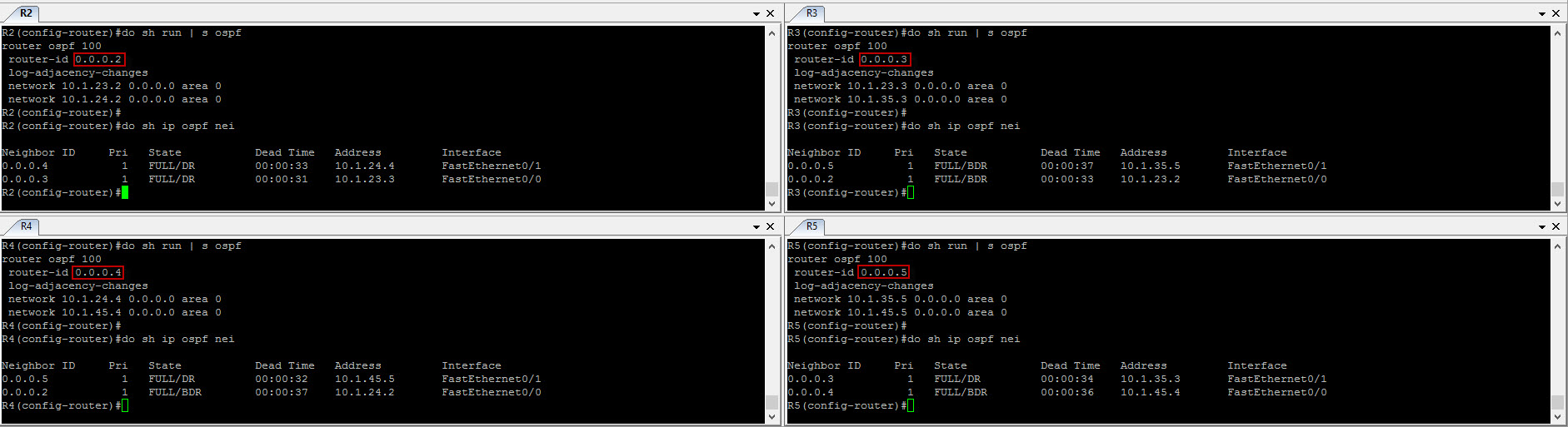
All right ! OSPF is now configured and you can see the neighbor relationship here. Notice how we defined the router-IDs ? Usually, loopback addresses are used but this also works. I want to show you something in regards to the router-IDs in the next few lines. Let’s configure BGP on R1 and announce the loopback prefix…

As you can see here, it is pretty straight forward. To enable the BGP process, we used the command “router bgp 100” with 100 being the AS number. Noticed the command “no bgp default ipv4-unicast” ? This is not a requirement as all it does is disable the automatic advertisement of routing information for the IPv4 address family. Since the command is entered, we needed then to configure the command “neighbor 10.1.12.2 activate” under the appropriate address family in order to establish the session. Again, this is not a requirement but I suggest to get familiar with this method as it will come in handy when deploying complex BGP solutions related to different address families.
We’ve also used the network command to advertise the 1.0.0.0/8 prefix. Notice here we did not need to add a mask as the prefix falls on a major network boundary.
Note that we could announce the prefix via the “network” command or the “aggregate” command. For a network prefix to be successfully announced to a peer via the network command, a component route must exist in the IP routing table. On the other hand, if a prefix is announced via the aggregate command then a component route must exist in the BGP routing table.
Have you also noticed the command “synchronization” ? It’s much more challenging if synchronization is enabled so we will do that. Note that the synchronization rule along with the split horizon rule (This is different from the Split Horizon in EIGRP) are loop prevention mechanism in BGP. Let me explain…
*Synchronization Rule: When this rule was created, full mesh iBGP peering was not common practice at the time. It basically states that when synchronization is enabled, a BGP router will not install iBGP learned routes in its routing table unless validated in its IGP.
If we take a look at topology above, R1 announce the loopback prefix to R2 via eBGP. Then an iBGP session is established between R2 and R5 so when R2 receives the routes, it transmits it to R5. So, R5 then advertise the route to R6 via eBGP which now fulfill the routing information flow. How about the traffic flow from R6 perspective ? R6 needs to connect to 1.0.0.0/8 through R5 which needs to go through either R3 or R4 right ? But neither R3 nor R4 knows about this network so the packet is dropped. That’s when the “Synchronization” rule come into play which resolved the next hop reachability issue as R3 and R4 would now know where to forward packets if OSPF adjacency is complete (Note that redistribution has to take place on R2 between BGP and OSPF or some form of policy announcing the R1 prefix at the border router).
*Split Horizon Rule: But with the requirement of redistribution or route injection with the sync rule, we’ve just created another problem… So at this point R2 is peering with R1 via eBGP and let’s say R1 has about 25000 routes in its routing table… It’s clear that OSPF can not handle that many routes so now the idea was to run full mesh iBGP session between the routers. However, R2 receives the prefix and advertises it to R3 and R4 right ? But R3 can then advertise the route to R5 and R5 in return advertises it back to R4 then R4 advertises the same prefix back to R2 which results in routing loops. That’s how the Split Horizon rule came into play. It basically states that an iBGP speaker will not advertise iBGP learned routes to another iBGP speaker unless it is configured as a confederation peer or a route reflector.
All right ! Now we have solved the routing loop scenario with the combination of those 2 rules. But imagine you’re working in the largest ISP worldwide managing a network of a couple thousand nodes. Can you imagine how much of a nightmare it would be if you were to maintain a full mesh network composed of thousands of routers ? It just does not scale ! That’s where “Confederation” and “Route Reflector” comes in. Let me explain…
Confederation: The idea was to reduce the amount of iBGP peering within a single AS. So, a confederation divides an autonomous system into multiple sub-autonomous systems while appearing as a single AS to the outside world. Routing information are exchanged between confederation as if they were iBGP peers. Hence, attributes like Next Hop, MED and Local Preference are preserved.
Route Reflector: A RR is the King of the Castle ! All iBGP speakers need to peer with the RR. The iBGP speakers are then called “Route Reflector Client”. The RR as the term implies, reflects routes among client peers. This is similar to the DR/BDR scenario in OSPF.
RR servers propagate routes inside the AS based on the following rules:
-If a route is received from nonclient peer, reflect to clients only.
-If a route is received from a client peer, reflect to all nonclient peers and also to client peers, except the originator of the route.
-If a route is received from an EBGP peer, reflect to all client and nonclient peers.
All right ! Let’s hop back onto the consoles and configure R2. Note that we will go through a few troubleshooting steps which will help tremendously in comprehending the protocol.

We can already see the console message letting us know that the eBGP peering has formed. Noticed here how the router-ID is 2.2.2.2 ? Let’s configure iBGP sessions in AS 65123. We will be configuring loopback addresses and advertise them in OSPF so we can use them as peering source with BGP…
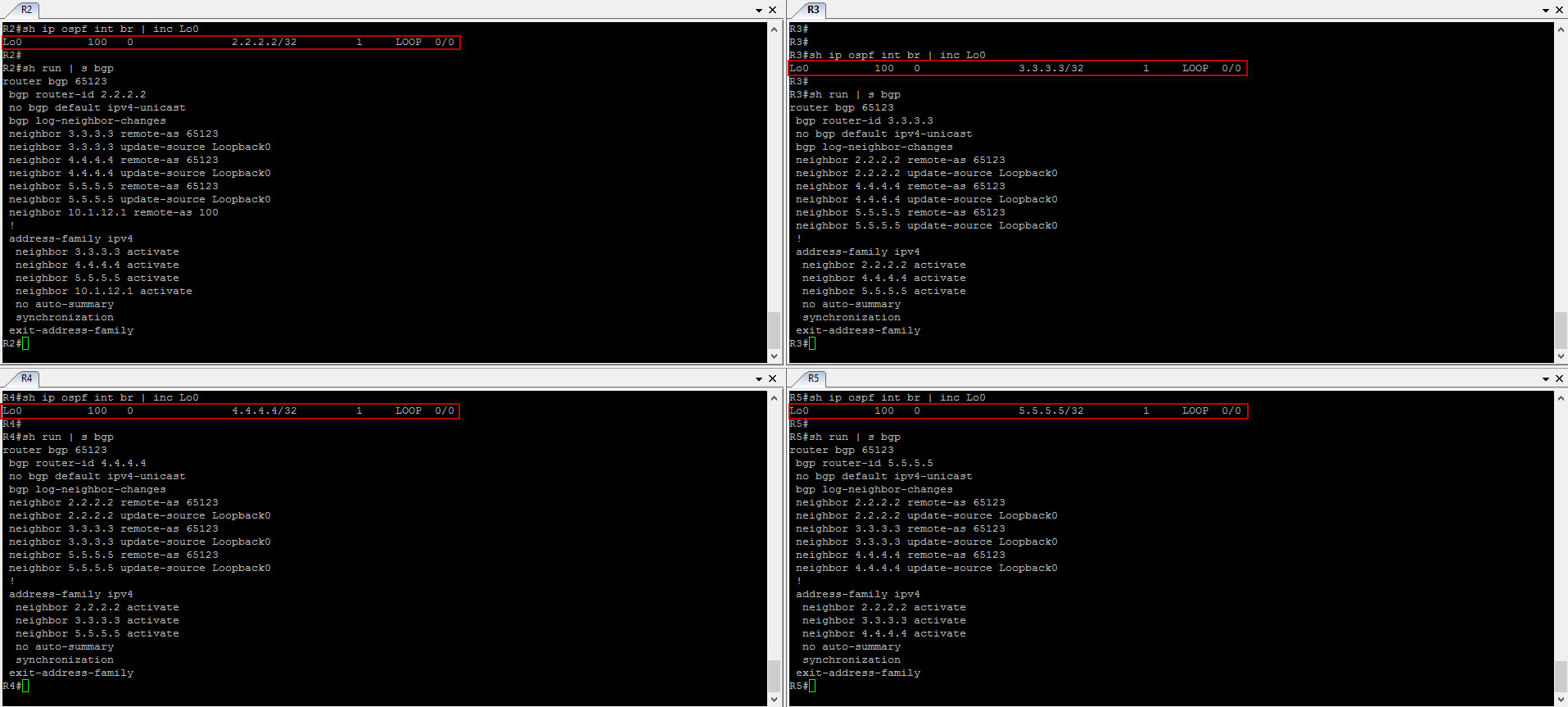
Okay good ! Let’s now configure the eBGP session between R5 and R6…

Let’s go back to R1 and check its BGP to make sure it is in fact originating the loopback prefix…

Good ! Also, noticed how the next hop here is 0.0.0.0 and the AS Path is empty ? This is actually what we are looking for because those are the characteristics of locally originated BGP routes.
Let’s now check and make sure our locally originated route is being advertised by R1…
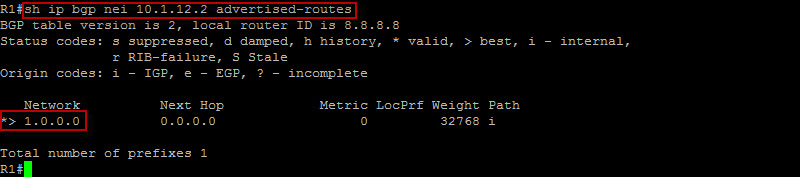
Perfect ! We can see here that R1 is advertising the 1.0.0.0/8 prefix to R2. Let’s now check R2 and see if we are receiving the loopback prefix…
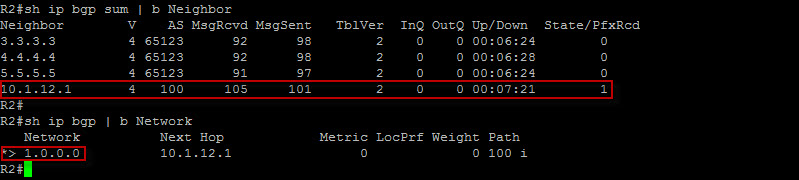
Here, we can see that in fact the BGP peering session is operational and the prefix is in the bgp routing table. Notice the “>” symbol indicating that this is the best path. This is very good ! Also, have you noticed here that the next-hop attribute is 10.1.12.1 which is the eBGP speaker originating the route and the AS Path is 100 ? By default the eBGP speaker sets the next-hop attribute and prepend its own AS to the AS path.
Let me show you how the entry appears in the routing table…
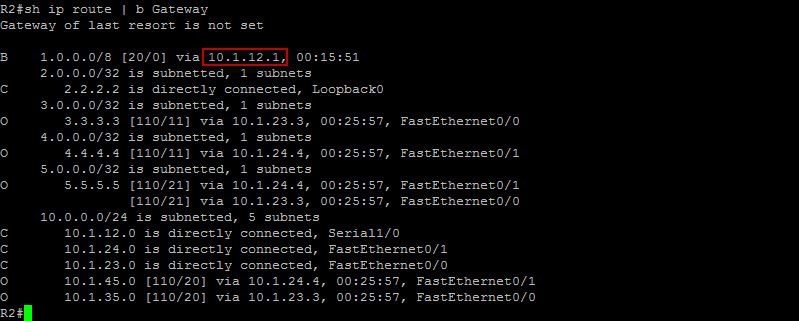
Notice here that the BGP routing table entry only references a next-hop and not an exit interface. By default, BGP is designed to forward packet to a next-hop AS and not a next hop router. Forwarding packets to a next hop router on a common subnet is the role of an IGP.
Let’s now redistribute BGP into OSPF on R2 so we can have the prefix as a component route across since we have enabled “Synchronization”. Note that that’s one way of doing it ! We could have also configure a static route referencing the prefix to Null 0 with a metric of 200 if no correspondent route exists in the IP routing table.

Done ! Let’s check and see if R3, R4 and R5 received the prefix with the greater than sign…
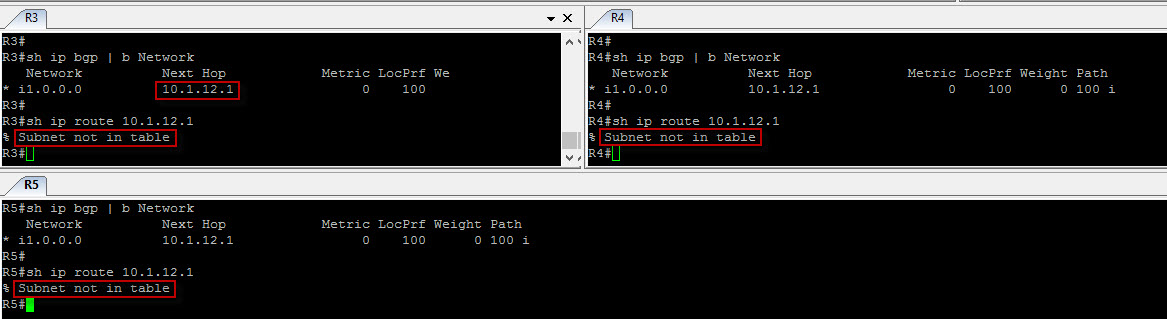
They did not ! here we do not see the “greater than” symbol which is a problem. We’ve already established that R1 advertised the loopback prefix to the upstream router (R2 in our case) along with the next hop attribute as itself (10.1.12.1 in our case). This is a default behavior as the next-hop attribute is set only by the last eBGP speaker and not by any iBGP speaker. However, if we look at the routing table of R3, R4 and R5 we can clearly see here that we do not have a route to the next hop address as R1 is not running OSPF. Therefore, both R3, R4 and R5 do not know how to get to the loopback prefix. Let’s fix that by modifying the next hop address attribute on R2…

Note that here we had several other options; We could have either redistributed the next-hop address into the local routing domain (OSPF in our case) or configure a route-map referencing a reachable next-hop on the upstream router (R2 in our case).
Great ! Let’s check R3, R4 and R5 again…

Fantastic ! The next hop attribute is now the border router IP address (2.2.2.2) which all R3, R4 and R5 have component route to; But there is still an apparent problem here. There is no “greater than” symbol for this prefix ! Therefore BGP will not use this route locally and will not advertise the route to its neighbor. The reason is the synchronization rule in conjunction with OSPF.

Another requirement of the synchronization rule is that if OSPF is the IGP in the AS (BGP), the router ID of the OSPF process and the BGP (Border router performing redistribution) process router ID MUST be the same. Let’s change the router ID of OSPF to match BGP’s…
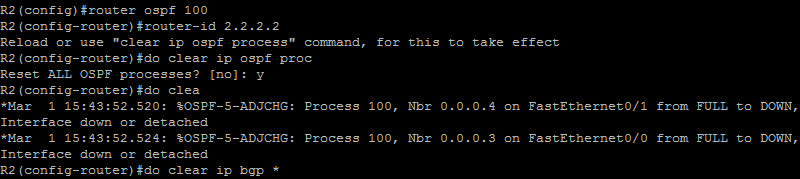
Good ! Let’s now check R3, R4 and R5 bgp table again…
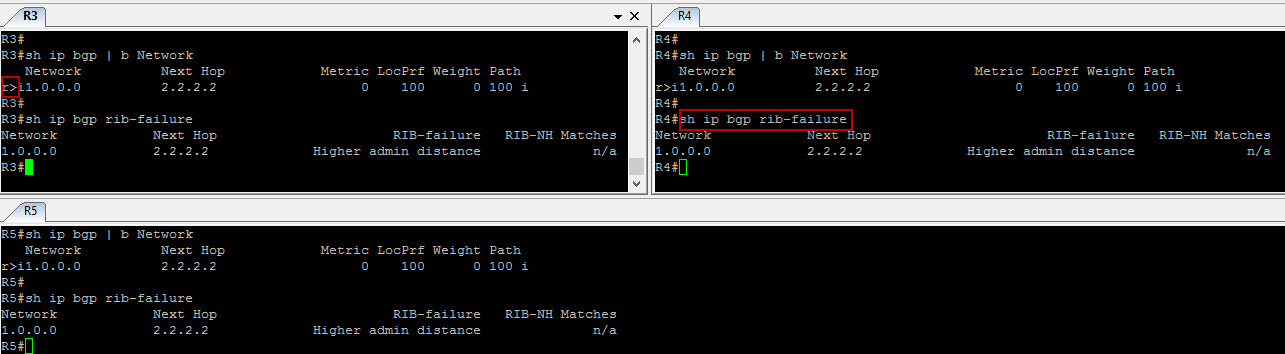
That’s better ! We now do have the “greater than” symbol ! Note that the “r” next to the “>” symbol is simply due to the fact that we already have a route with better administrative distance already present in IGP.
Now that we have the prefix in R5 BGP table and routing table. Let’s check and make sure R5 is advertising the prefix to R6…
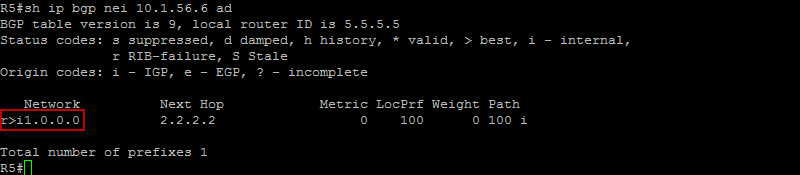
Great ! Let’s see if R6 accepted the prefix…

Fantastic ! The prefix successfully made it across ! Now in order to successfully ping across, the 10.1.56.0/24 prefix needs to be known since R6 exit interface is 10.1.56.6. Let’s advertise it on R5 via OSPF…
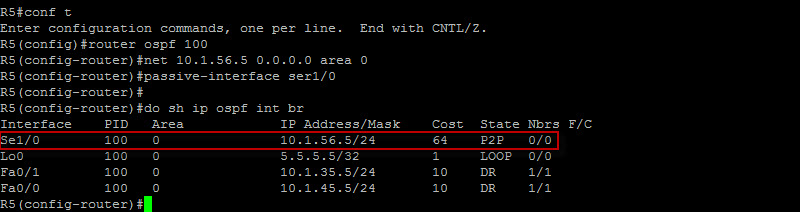
Let’s see if we can now ping the prefix from R6…
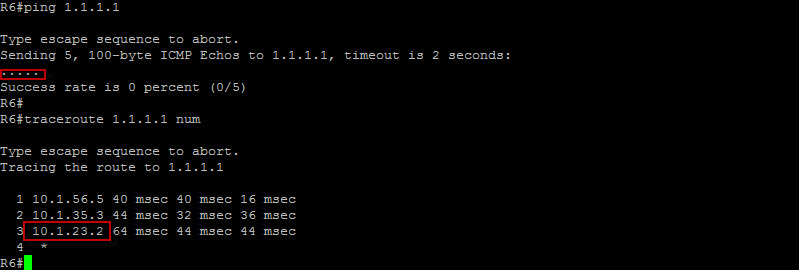
We still can not but if we look at the traceroute output, we can clearly see that the last reachable hop is in fact R2 which tells us the problem is situated on R1. Let’s head to R1…

Since the ping is originating from R6, that means that R1 should know how to get back to R6. Here we can clearly see that we do not have a route to the 10.1.56.0/24 prefix or at least a default route pointing to R2. Let’s create a component route for the 10.1.56.0/24 prefix on R1…

Let’s try our ping test again from R6…

Okay ! We are now able to ping across the transit path to R1 from R6.
You can download the GNS3 file pertaining to this lab here.
This completes the topic. Take care.
 Hi, I'm Pape ! Folks call me Pop. I'm CCIE #48357. I love what I do and enjoy making tech easier to understand. I also love writing, so I’m sharing my blog with you
Hi, I'm Pape ! Folks call me Pop. I'm CCIE #48357. I love what I do and enjoy making tech easier to understand. I also love writing, so I’m sharing my blog with you
| M | T | W | T | F | S | S |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
“That’s better ! We now do have the “greater than” symbol ! Note that the “r” next to the “>” symbol is simply due to the fact that we already have a route with better administrative distance already present in IGP.”
Can you please explain a bit more on this . Where is the better route in IGP ? Your articles are pretty good and I am going thorugh most of them and it is helping me alot
Hello Arindam,
I’m assuming you’re referring to the prefix displayed in the BGP table from R6 ? The command ran was “sh ip bgp” which displays only BGP routes. A “show ip route” command would display the main routing table specific to any protocol being ran on the device as well as connected/redistributed routes.